

5 Stap 3 — Analyse van gedeelde foutoorzaken
Bepaal en analyseer gedeelde foutoorzaken.
Een gedeelde foutoorzaak is een gebeurtenis die leidt tot de gelijktijdige uitval van twee of meer componenten. Een voorbeeld: twee kabels in dezelfde buis kunnen beide worden doorgesneden in een en hetzelfde incident, meerdere apparaten kunnen verwoest worden tijdens een brand.
Om een gedeelde foutoorzaak te hebben, moeten de getroffen componenten voldoende dichtbij zijn, gemeten naar een kenmerkende eigenschap. Voor fysieke uitval zoals brand of overstromingen, is die eigenschap geografische nabijheid; de componenten moeten dicht genoeg bij elkaar staan om gelijktijdig getroffen te kunnen worden. Voor configuratiefouten zit de gezamenlijkheid in onderhoudsprocedures. Voor softwarefouten kan het zijn dat verwante versies van bepaalde firmware is gebruikt, en dat staat los van de geografische afstand. Andere gebeurtenissen kunnen andere kritische eigenschappen hebben.
Voor ieder uitvalscenario geldt dat elke kenmerkende eigenschap een maximale afstand heeft om effect te kunnen hebben. Twee apparaten kunnen alleen getroffen worden door een kleine brand als ze beide in dezelfde kamer staan; voor een grote brand is de afstand om effect te kunnen hebben groter, maar nog altijd beperkt tot wellicht een gebouw. Een overstroming heeft op een veel groter effectgebied en twee componenten moeten dan ook verder van elkaar af staan om immuun te zijn voor een overstroming als gedeelde foutoorzaak.
In stap drie zult u groepen maken van componenten binnen hetzelfde bereik van een kenmerkende eigenschap. U doet dit voor elke kwetsbaarheid op zich. Van elk cluster beoordeelt u vervolgens de Frequentie en de Impact van een gedeelde foutoorzaak op de componenten in dat cluster. De clusters en de bijbehorende beoordelingen worden vastgelegd in de Raster applicatie. Het eindresultaat is een verbeterde en verfijnde risicobeoordeling.
De analyse van gedeelde foutoorzaken bestaat uit de volgende stappen:
5.1 Maak clusters
De Raster applicatie maakt automatisch een lijst aan van alle gebruikte kwetsbaarheden, mits de kwetsbaarheid voorkomt bij tenminste twee componenten. Voor elke kwetsbaarheid moeten de analisten clusters maken op basis van de kenmerkende eigenschap.
Voorbeeld: clusters op basis van geografische nabijheid kunnen worden gebruikt bij branden, overstromingen, stroomuitval, kabelbreuken en radio jamming (per frequentieband).
Clusters op basis van organisatorische grenzen kunnen worden gebruikt voor de configuratie van apparatuur, veroudering en softwarefouten. In eerste instantie plaatst de Raster applicatie alle componenten met een zelfde kwetsbaarheid in één cluster. Op basis van het bereik van het uitvalsscenario kunnen verdere onderverdelingen gemaakt worden zodat:
- elk cluster overeen komt met uitvalsscenario’s met dezelfde locatie en bereik.
- een uitvalsscenario voor een cluster nooit componenten buiten dat cluster treffen.
- een uitvalsscenario twee componenten binnen hetzelfde cluster kan raken.
Het is mogelijk dat er in een groot cluster een kleiner cluster is opgenomen. Clusters kunnen dus genest zijn. Alle componenten binnen een subcluster zijn ook onderdeel van het hoofdcluster.
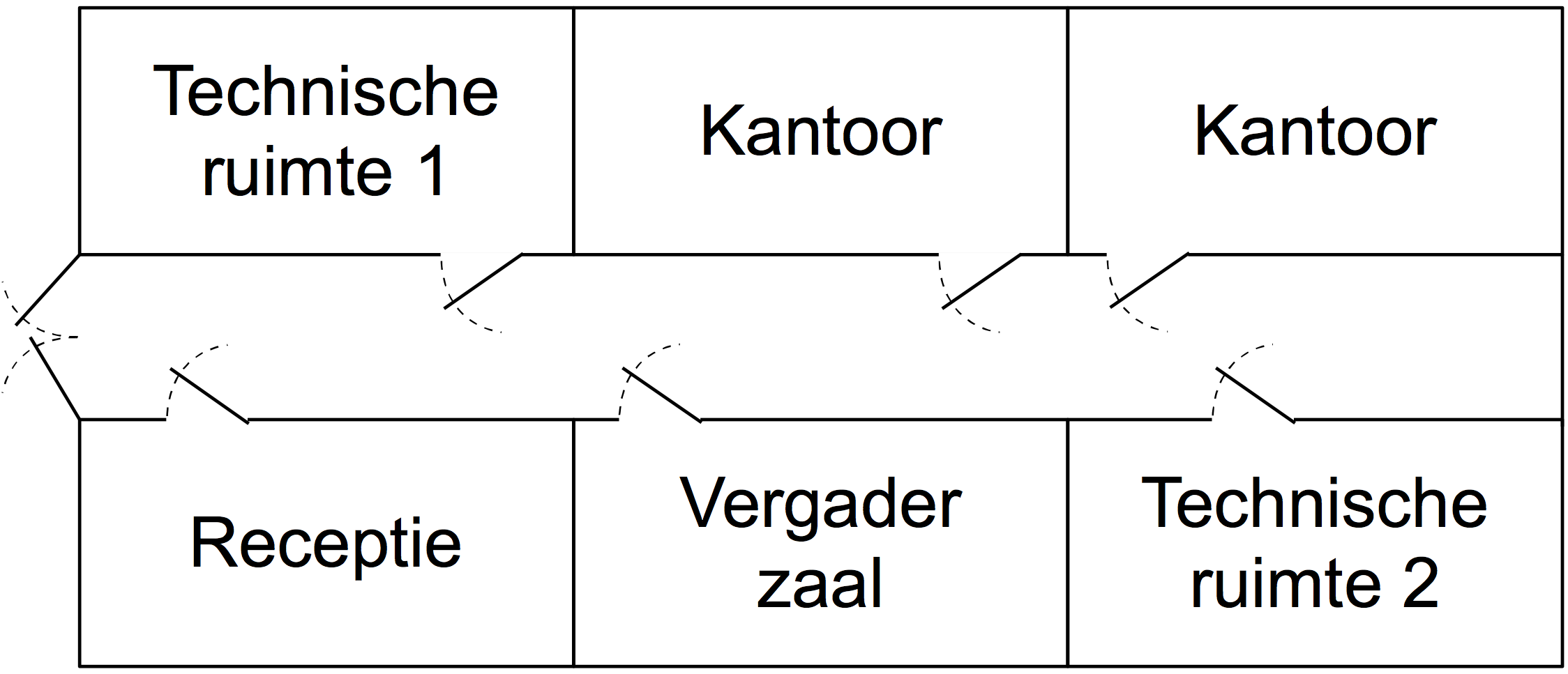
Een voorbeeld, de figuur rechts verbeeldt een kantoorplattegrond met twee ruimtes voor apparatuur. Er zijn drie clusters mogelijk:
- Apparatuur ruimte 1 – kleine brand treft alleen componenten in ruimte 1.
- Apparatuur ruimte 2 – kleine brand treft alleen componenten in ruimte 2.
- Het complete kantoor – grote brand treft alle componenten in alle ruimtes.
Cluster 3 bevat subclusters 1 en 2. Zie hoe elk cluster specifiek betrekking heeft op een bepaalde kwetsbaarheid (brand) en scenario's heeft met hetzelfde locatie- en effectgebied.
De Raster applicatie maakt clusters in het Gedeelde foutenscherm.
5.2 Analyseer elk cluster
Om een cluster te kunnen analyseren moeten de factoren Frequentie en Impact worden beoordeeld. Dit wordt op soortgelijke manier gedaan als bij enkele foutoorzaken (zie Analyseer de kwetsbaarheden van componenten).
In deze stap is de factor Frequentie een weergave van de waarschijnlijkheid dat twee of meer componenten binnen een cluster getroffen worden door het uitvalsscenario. Het is dus niet vereist dat alle componenten in het cluster getroffen worden. Een Impact-klasse is van toepassing als het uitvalsscenario leidt tot een incident dat één of meer telecomdiensten raakt. Bijvoorbeeld: als drie componenten in een cluster gezamenlijk uitvallen en daardoor één telecomdienst langdurig geheel onbeschikbaar raakt, dan is de Impact klasse Hoog van toepassing op dat cluster.
De Raster applicatie zal automatisch het kwetsbaarheidsniveau berekenen van eventuele hoofdclusters, met inbegrip van de kwetsbaarheid op het hoogste niveau.
5.3 Werk onverkende verbindingen uit
Als een cluster dat onverkende verbindingen bevat een totaal kwetsbaarheidsniveau van Onbekend of Tegenstrijdig heeft, moeten de analisten bepalen of ze deze onverkende verbindingen verder uitwerken of niet. Dit is in analogie met de uitwerking in de stap van enkele foutoorzaken (zie Werk onverkende verbindingen uit).
Het is niet altijd nodig om onverkende verbindingen verder uit te werken. Als de analisten denken dat de moeite die erin gestoken moet worden te groot is of niet tot een nauwkeuriger of meer verhelderend resultaat leidt, dan kan verdere uitwerking achterwege blijven.
Een verdere uitwerking leidt tot toevoeging van nieuwe componenten aan het diagram. Deze nieuwe componenten moeten worden geanalyseerd op enkele foutoorzaken. Dit betekent dat Stap 2 opnieuw moet worden uitgevoerd voor deze componenten. Het betekent ook dat sommige clusters nieuwe componenten krijgen. Ook de analyse van deze clusters moet dan worden herzien.
5.4 Review
Tijdens de laatste review moeten de analisten de uitkomsten van de analyses van enkele en gedeelde foutoorzaken bespreken. Er moet speciale aandacht zijn voor de consistentie van de beoordelingen. De volgende stap kan alleen gestart worden als alle analisten het eens zijn over de resultaten van de analyses.
Als een cluster een kwetsbaarheidsniveau heeft van Tegenstrijdig of Onbekend, dan moeten de analisten bepalen of ze verder onderzoek gaan doen om de gedeelde foutoorzaken met meer zekerheid te kunnen beoordelen. Als de analisten denken dat de moeite die erin gestoken moet worden te groot is of niet tot een nauwkeuriger of meer verhelderend resultaat leidt, dan kan verdere uitwerking achterwege blijven.
Als de analisten besluiten om een aanzienlijk deel van de analyse van gedeelde foutoorzaken over te doen, dan moet er na afloop een nieuwe review plaatsvinden.